https://arxiv.org/pdf/1502.05477.pdf
We describe a iterative procedure for optimizing policies, with guaranteed monotonic improvement. By making several approximations to the theoretically-justified procedure, we develop a practical algorithm, called Trust Region Policy Optimization (TRPO). This algorithm is similar to natural policy gradient methods and is effective for optimizing large nonlinear policies such as neural networks. Our experiments demonstrate its robust performance on a wide variety of tasks: learning simulated robotic swimming, hopping, and walking gaits; and playing Atari games using images of the screen as input. Despite its approximations that deviate from the theory, TRPO tends to give monotonic improvement, with little tuning of hyperparameters.
给出了一个迭代式优化策略的方法,保证单调改进. 通过对经理论验证的过程的几个近似,我们设计了一个实用的算法,称为 Trust Region Policy Optimization(TRPO),这个算法类似于 natural Policy gradient,对优化大型非线性策略(如神经网络)非常有效. 我们的实验展示了在众多不同的任务上(如学习模拟机器人游泳、跳跃和行走;使用游戏图像学习玩 Atari 游戏)健壮的性能. 尽管近似跟理论结构有所偏离,但是 TRPO 还是给出了单调的提升,也不需要太多的超参数调优.
引言
大多数策略优化的算法可以被分成:a. 策略迭代方法,轮换地估计当前策略下的值函数和提高策略(Bertsekas, 2015);b. 策略梯度方法,使用从样本轨迹获得的期望回报(总共奖励)的梯度的估计(Peter & Schaal, 2008a)(这个方法其实和策略迭代方法有很密切的关联);c. 免导数优化方法,如 交叉熵方法(CEM)和协方差矩阵适应(CMA),将回报当做是一个黑盒函数使用策略参数进行优化(Szita & Lörincz,2006).
通常的免导数随机优化方法适用于很多问题,因为他们能够获得很好的结果,也容易理解和实现. 例如 Tetris 是近似动态规划方法的经典的 benchmark 问题,随机优化方法其实在这个问题表现超过近似动态规划方法. 对于连续控制问题,如 CMA 的方法已经能够在给定低维度参数化的手工特征策略类情况下成功学习控制策略了(Wampler & Popvić,2009). ADP 和基于梯度的方法并不能一致性地超过免梯度随机搜索其实不太令人满意,因为相比免梯度方法,基于梯度优化的算法有着更加好的采样复杂度保证(Nemirovski,2015). 连续基于梯度优化已经在监督学习中的函数近似上表现神勇,并且将其成功迁移到强化学习上应该可以给出更加高效的复杂和强大策略的训练.
在本文中,我们首先证明最小化某个 surrogate 目标函数保证了策略依照非平凡的步长进行提升. 接着我们对理论验证算法进行一系列的近似,得到一个实际算法,这个我们称为 信頼域策略优化(TRPO)算法. 我们给出了这个算法的两个变种:1. 单路径 方法,可以应用在无模型场景下;2. vine 方法,要求系统可以由特定的状态进行重生,这个在模拟中是比较常见的. 这些算法都是可扩展的,并且可以优化上万参数的非线性策略,这其实是之前免模型策略搜索方法的主要挑战之一(Deisenroth等人,2013). 在我们的实验中,同样的 TRPO 算法可以学到复杂的游泳、跳跃和行走的策略,也能够学会玩 Atari 游戏.
预备知识
考虑一个无穷长度的折扣 MDP(Markov Decision Process),定义为元组 $(\mathcal{S},\mathcal{A},P,r,\rho_0,\gamma)$,其中 $\mathcal{S}$ 为有穷状态集,$\mathcal{A}$ 为有穷行动集合,$P:\mathcal{S}\times \mathcal{A} \times \mathcal{S} \rightarrow \mathbb{R}$ 是转移状态分布,$r:\mathcal{S} \rightarrow \mathbb{R}$ 是奖励函数,$\rho_0:\mathcal{S} \rightarrow \mathbb{R}$ 是初始状态 $s_0$ 的分布,而 $\gamma \in (0,1)$ 是折扣因子.



 .
. ,我们可以简单地最大化监督学习的目标函数:
,我们可以简单地最大化监督学习的目标函数:
 . 令
. 令  表示收益的和:
表示收益的和: . 最简单的策略梯度公式就是:
. 最简单的策略梯度公式就是: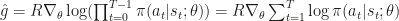
 ,我们可以用一个梯度上升的步骤,
,我们可以用一个梯度上升的步骤, 进行策略的更新,其中
进行策略的更新,其中 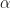 为学习率. 我们会收集所有的回合,对那个回合中所有的行动的对数概率按照回合的总收益
为学习率. 我们会收集所有的回合,对那个回合中所有的行动的对数概率按照回合的总收益 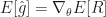
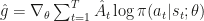
 是行动
是行动  的有利度 (advantage)的估计——比平均值好还是坏的程度.
的有利度 (advantage)的估计——比平均值好还是坏的程度.
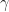 是折扣因子,
是折扣因子,
 的近似.
的近似.  的时间步的影响.
的时间步的影响.  ,那么我们如何使用一个神经网络进行表示?实际上,我们仅仅需要将
,那么我们如何使用一个神经网络进行表示?实际上,我们仅仅需要将  映射到某个向量
映射到某个向量  上,向量描述了行动
上,向量描述了行动  上的分布. 例如,
上的分布. 例如, 的深度神经网络
的深度神经网络  来表示策略,定义目标函数为总折扣奖励
来表示策略,定义目标函数为总折扣奖励

 的方向
的方向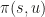

 的值函数
的值函数 













 ) is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that, even if those events are in reality executed out of order (usually to optimize program flow). This involves
) is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that, even if those events are in reality executed out of order (usually to optimize program flow). This involves 


